
Extracting and Mapping Location Mentions From Texts To The Ground
7:38:00 PMby Unknown
The meaning of a social media post can be a function of location. For example, the meaning of "The Main Street bridge is closed" is ambiguous without establishing exactly which bridge is in question (The one in Danville, VA or in Columbus, OH). At the same time, location information metadata is sparse, forcing analysis of social media content and context to disambiguate alternative mappings. This article uncovers some of the persisting challenges in the recovery of location information from content and context: Text normalization, ambiguous location information, Geoparsing, and the future steps of our research.
Consider the Tweet in Figure 1. It contains valuable, but implicit information for Disaster Response and Flood Modeling. Here the user provides the level of water during a storm surge. Knowledge-based inference supports the enrichment of this claim to determine that the water level is around 3 meters (to the height of a first floor)1. If we knew the location of Ganapathi colony, this quantitative data can inform a storm surge model to predict the direction of the surge and the danger it might pose.
Consider the Tweet in Figure 1. It contains valuable, but implicit information for Disaster Response and Flood Modeling. Here the user provides the level of water during a storm surge. Knowledge-based inference supports the enrichment of this claim to determine that the water level is around 3 meters (to the height of a first floor)1. If we knew the location of Ganapathi colony, this quantitative data can inform a storm surge model to predict the direction of the surge and the danger it might pose.
#ChennaiRainsHelp water hitting first floor. need to evacuate Ganapathi colony. @ChennaiRains @ndtv pic.twitter.com/rNvx4i4JVH— Balaji (@blaji) December 2, 2015
Fig. 1: An example tweet from Twitris campaign of Chennai Flood 2015.
At Kno.e.sis center, one of the goals of our NSF-funded project (Social and Physical Sensing Enabled Decision Support) is to make information available in social media accessible to first-responders to prioritize relief efforts. Mapping events to locations in order to attach ground-based information to locations on the map will allow us to achieve the desired goal. In contrast to physical sensors, the resolution of social media data is a function of population rather than specialized infrastructure. In the case of lack of sensor/IoT coverage or malfunctioning of sensors, citizen sensing can provide information about ground status to compensate for missing data.
Using Twitris, Kno.e.sis’ robust semantic social web platform that has been used in a number of real-world scenarios, we collect real-time, event-centric twitter data to understand social perceptions. During the 2015 Chennai floods, we created a Twitris campaign that collected around 508K relevant tweets. Determining location is an important part of making these tweets informative. Location extraction and mapping is performed in two steps: Toponym extraction and Geoparsing.
Toponym Extraction
Toponym extraction is the process of extracting names of places from texts such as street names, points of interest (POI), cities, countries, and so on. There are two traditional ways to extract toponyms from texts: a supervised approach and an gazetteer-matching approach.
Supervised approaches. In the supervised approach, we train the model using manually annotated data of location mentions [1], Supervised approaches tend to suffer from the underestimation of missing data. They require sufficient amount of annotated data from the same data source (e.g., microblog text), to enable location detections from similar data sources. However, the gazetteer approach discussed next has its own difficulties and issues that must be solved to extract locations from texts efficiently.

Fig. 2: Syntactic Parse tree built using NLTK's cascaded chunk parser.
Gazetteers approaches. In the gazetteer approach, we extract location mentions on the fly without using any training dataset. Gazetteer approaches often use syntactic parse trees (for noun phrase extraction), direction and distance markers, gazetteers, dictionaries and many other knowledge bases in order to extract locations from texts [2-4]. Figure 2 shows part of the parse tree built using NLTK of the tweet text in Figure 3. Parsing the tweet text allows us to find noun phrases using the NLTK’s cascaded chunk parser. The parser matches a set of predefined rules to text. For example, the rule ( VP: {<VB.*><NP|PP|CLAUSE>+$} ) allows us to detect and extract the noun phrase (NP) “SRM university” which follows the preposition (PP) “Near”.
Please evacuate us from area Near SRM university, kattankulathur. No food.. No current.. Nothing is here . #ChennaiRains #ChennaiRainsHelp— Rohit kumar singh (@imRohit09) December 1, 2015
Fig. 3: Tweet mentioning the toponyms “SRM university” and “kattankulathur”.
Similarly, direction and distance markers allow us to retrieve toponyms the markers are pointing at. For example, in Figure 4. The direction marker “south of” points at the toponym “101 Fwy” which is then added to our list of potential geo-parsable toponym names.
THIS JUST IN: Power out in #StudioCity after reports of loud explosion in area south of 101 Fwy between Woodman Ave and Coldwater Canyon.— ABC7 Eyewitness News (@ABC7) April 7, 2016
Fig. 4: Tweet mentioning a toponym (“101 Fwy”) pointed at by a direction marker
Two challenges arise in Toponym extraction: Text normalization and ambiguous location information.
Text normalization. Text normalization involves subtasks such as abbreviations and acronyms expansion and misspelling corrections. Figure 5 shows an example of a tweet with such difficulties. The author of the tweet used “Rd” as an abbreviation of “road”. Moreover, the text “Kilpauk Garden” is incomplete relative to the Gazetteer name “Kilpauk, Aspiran Garden Colony”2.
2 ppl need to be evacuated frm #21, New Avadi Rd, Kilpauk Garden (Nr. Zam Zam Bakery) Contact 9841546767 #ChennaiRainsHelp #chennairains— Raj!n! Followers™ (@RajiniFollowers) December 1, 2015
Fig. 5: An example tweet with abbreviations (Rd) and incomplete information (Kilpauk Garden).
Locations can also be embedded in hashtags or usernames. For example, both @yankeestadium and #YankeeStadium refer to the location name “Yankee Stadium”. Therefore, such location mentions can also be extracted using a word segmentation (tokenization) method. The method uses a classifier on unigram and bigram language models of word frequencies to find word boundaries.
Locations can also be embedded in hashtags or usernames. For example, both @yankeestadium and #YankeeStadium refer to the location name “Yankee Stadium”. Therefore, such location mentions can also be extracted using a word segmentation (tokenization) method. The method uses a classifier on unigram and bigram language models of word frequencies to find word boundaries.
Ambiguous Location Information. Location information is not always explicit. The relative directionality and distance content noted above hints at this problem. Consider the following tweet (Figure 6) as a more challenging example:
Our house in Chennai fully flooded. Everyone evacuated safely. My brother trying to get there from Mumbai...— Karun Chandhok (@karunchandhok) December 2, 2015
Fig. 6: A tweet showing an ambiguous mention of a location.
In this example, a renowned author (Indian racing driver Karun Chandhok) is referring to his parent’s house. Ideally, the location of the house could be extracted from a knowledge base. The extracted toponym “our house” should then be mapped to an absolute location name. This extracted piece of information can then provide us with the fact that people are evacuating from his parents’ area. For another example of using a knowledge base (or location database) to identify a building name (Nariman House) is shown in Figure 2 of this article on Citizen Sensing.
Geoparsing
Geoparsing contrasts with geocoding, and both follow toponym extraction. Geocoding works with unambiguous location references such as postal addresses to specify a location on Earth using coordinates (latitude and longitude). Geoparsing is similar to Geocoding but differs in that it works with ambiguous location references in unstructured texts (such as tweets).
Geoparsing can be performed through a gazetteer matching process that allows us to retrieve all the metadata of the matched location. OpenStreetMap, for example, provides information such as the bounding box, the latitude and longitude, the full address, the class of the location name (Map Features), and the full display name of the matched toponym. The information extracted after a successful gazetteer matching pinpoints the toponym on the map and attaches to it the extracted metadata. The following map (Figure 7) shows the mapped toponym from the tweet in Figure 5.
Geoparsing can be performed through a gazetteer matching process that allows us to retrieve all the metadata of the matched location. OpenStreetMap, for example, provides information such as the bounding box, the latitude and longitude, the full address, the class of the location name (Map Features), and the full display name of the matched toponym. The information extracted after a successful gazetteer matching pinpoints the toponym on the map and attaches to it the extracted metadata. The following map (Figure 7) shows the mapped toponym from the tweet in Figure 5.
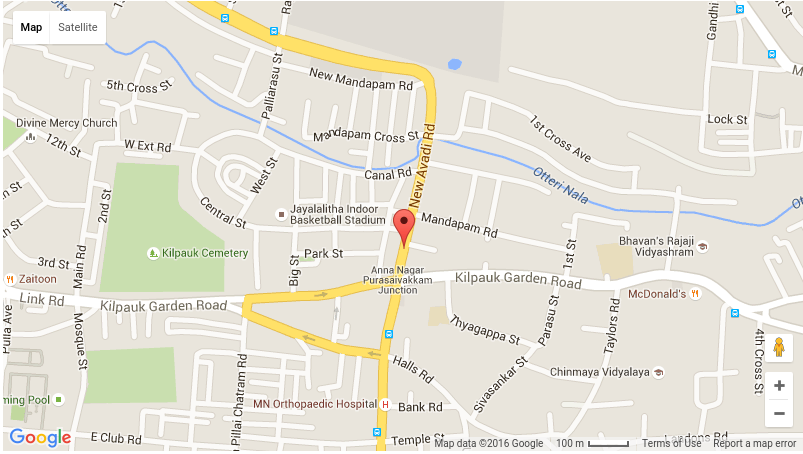
Fig. 7: Pinpointing the full location name of the extracted toponym from the tweet in Figure 5: “No. 17/7, New Avadi Road, Kilpauk, Aspiran Garden Colony, Kilpauk, Chennai, Tamil Nadu 600010, India”
A typical gazetteer matching task requires complex text normalization and missing data restoration. To overcome some of the difficulties posed by Twitter data we typically use fuzzy text matching during toponym extraction, in addition to the previously discussed text normalization process. As for the incompleteness of gazetteers, a combination of one or more additional knowledge bases can be used. An example of such dictionaries is a list of points of interest3 that can be retrieved from an external data source.
Other things our research is addressing is the problem of disambiguation during Geoparsing. If a toponym name has many records in the gazetteer, the method should reasonably disambiguate which location the tweet was referring to. This problem includes the Whole-Part Relationship (i.e., which section of the road and which campus of a university). Using the provided context from text as shown in Figure 4, where the toponym “101 Fwy” is supposed to be “between Woodman Ave and Coldwater Canyon”, can tremendously help in solving such problems. Our research is currently investigating such problems and possible solutions.
Conclusions
Toponym extraction and Geoparsing require more than text normalization and the retrieval of unambiguous location names from the text. The disaster relief scenario aids in the identification of several important, and the research challenges yet to be solved well, such as ambiguous location information and more advanced Geoparsing disambiguations. The Kno.e.sis center's mission “Computing for Human Experience”, drives the recognition of these challenges while providing ground impact beyond lab implementations.
1 The issue of reliability and trustworthiness of the extracted information are relevant to our project but are not discussed here.
2 The correct location found using Google Maps goo.gl/AN9Gxr
3 Area specific points of interest (for example, in Chennai) are typically businesses, hospitals, shopping malls, etc.
References:
[1] Lingad, John, Sarvnaz Karimi, and Jie Yin. "Location extraction from disaster-related microblogs." In Proceedings of the 22nd international conference on World Wide Web companion, pp. 1017-1020. International World Wide Web Conferences Steering Committee, 2013.
[2] Gelernter, Judith, and Shilpa Balaji. "An algorithm for local geoparsing of microtext." GeoInformatica 17, no. 4 (2013): 635-667.
[2] Gelernter, Judith, and Shilpa Balaji. "An algorithm for local geoparsing of microtext." GeoInformatica 17, no. 4 (2013): 635-667.
[3] Shervin Malmasi, Mark Dras. “Location Mention Detection in Tweets and Microblogs”. Computational Linguistics. Volume 593 of the series Communications in Computer and Information Science pp 123-134. Springer February 2016.
[4] Middleton, Stuart E., Lee Middleton, and Stefano Modafferi. "Real-time crisis mapping of natural disasters using social media." Intelligent Systems, IEEE 29, no. 2 (2014): 9-17.
Parent Project


80 comments
Best Casino games, bonuses and promotions (November 2021
ReplyDeleteBest casino games, bonuses and promotions (November 2021 밀양 출장안마 부천 출장마사지 서울특별 출장안마 전주 출장안마 Casino Review 2021 | Avis Casino UK | 태백 출장안마 Free Spins | No Deposit Bonus.
Very helpful advice on this article! It is the little changes that make the biggest changes. Thanks a lot for sharing! 사설토토
ReplyDeleteI just stumbled upon to this blog and I enjoyed it.
ReplyDelete바카라사이트
카지노사이트
온라인카지노
바카라사이트닷컴
Been searching for simple article like this. Thanks to your writing.
ReplyDelete온라인카지노
바카라사이트
카지노사이트
온라인카지노
Thank you for the very useful information.
ReplyDelete스포츠토토링크는
스포츠토토
Really a nice article. Thank you so much for your efforts.
ReplyDelete온라인카지노
카지노
Definitely, it will be helpful for others
ReplyDelete바카라사이트
온라인카지노
Thanks for sharing the information keep updating, looking forward to more post.
ReplyDeleteNice post ! I love its your site after reading ! thanks for sharing. I am so happy to read this. This is the kind of manual that needs to be given and not the random misinformation that’s at the other blogs. Appreciate your sharing this greatest doc.
defending against protective order in virginia
domestic violence protective orders in virginia
I am happy to see a wonderful post. The information you are shared in this post is very informative and creative. The creative ideas behind is awesome. Thanks for sharing. Traffic Lawyer Frederick VA
ReplyDeleteKnoesis is a research center that focuses on various aspects of data and knowledge management, including areas like semantic web technologies, big data analytics, and artificial intelligence. While I don't have specific information about Knoesis beyond my last knowledge update in September 2021, I can provide a general review of research centers like Knoesis based on their typical characteristics:Accidente Camión de Fedex
ReplyDeleteKnoesis is a research group and center at Wright State University, specializing in various aspects of computer science and informatics, particularly focusing on data and knowledge engineering, semantics, and data analytics. Knoesis has been involved in a wide range of research projects and academic activities. However, it's important to note that Knoesis itself is not a product or service, so reviews in the traditional sense may not be readily available.abogados de accidentes
ReplyDelete
ReplyDeleteAbogado por Accidente de Motocicleta "Extracting and Mapping Location Mentions from Texts to the Ground" is a groundbreaking study in geospatial data processing, utilizing natural language processing and geographic information systems to extract and map location data from textual sources. This interdisciplinary research reduces manual labor and automates geospatial data extraction, offering practical benefits in fields like urban planning, disaster response, and social sciences. The research bridges the gap between unstructured textual information and structured geospatial data, offering significant implications for location-based decision-making and analysis. The method's versatility and scalability make it a valuable resource for professionals and researchers in geospatial fields. The work exemplifies the power of combining advanced technologies to unlock valuable geographic insights from textual data sources.
The accuracy and precision in identifying and plotting locations is impressive, and the mapping process is seamless. The visual representation of the data provides a clear understanding of the data. The reviewer is impressed with the efficiency of the task, the attention to detail in mapping the locations, and the informative visual output. The reviewer appreciates the dedication to quality and professionalism of the team. The seamless integration of location data into the project is a testament to the technical proficiency, and the team's ability to adapt to different data sources and formats is a valuable skill. The reviewer concludes that the team's expertise in extracting and mapping locations is crucial for ensuring the accuracy of spatial analyses.Good Car Accident Attorney VA
ReplyDeleteAddressing location extraction challenges is crucial for improving disaster response using social media data. Your work in enhancing toponym extraction and handling ambiguous location information is commendable.
ReplyDeleteDivorcio en Estado de Nueva York ¿Cuánto Tiempo Lleva?
Amelia Conducción imprudente
ReplyDeleteLa conducción imprudente en Amelia, Virginia, puede tener consecuencias legales significativas. Si enfrentas cargos por conducción imprudente en Amelia, es crucial buscar la asesoría de un abogado especializado en leyes de tráfico. Un abogado con experiencia en este campo puede ayudarte a entender tus derechos, evaluar la evidencia en tu caso y trabajar en tu defensa. No dudes en ponerte en contacto con un abogado de tráfico en Amelia para obtener asesoramiento legal específico y determinar la mejor estrategia para tu situación.
Your blog is a great example of how online content can be both informative and engaging - keep up the fantastic work!DUI Lawyer Prince William County VA
ReplyDeleteThis text explores the challenges and methodologies in extracting and mapping location mentions from texts to ground references, focusing on leveraging social media content during crisis situations like natural disasters. It discusses techniques like toponym extraction and geoparsing, highlighting complexities encountered and methods employed to resolve them. The ultimate goal is to make real-time social media data actionable for first responders in disaster scenarios, ensuring its reliability and relevance. The approach is comprehensive, leveraging tools like Twitris and NLTK while integrating multiple data sources and knowledge bases for accurate location extraction. The text emphasizes the importance of text normalization to handle abbreviations, misspellings, and incomplete location references in social media content. Geoparsing involves matching ambiguous location references to specific coordinates, using gazetteer matching processes and integrating multiple knowledge bases. Addressing complexities of disambiguation during geoparsing remains a key research focus. The text highlights the need for a more nuanced approach beyond text normalization and the importance of disambiguating location mentions and ensuring the reliability of extracted information. abogado de accidentes de camiones
ReplyDeleteThe review comment is a comprehensive evaluation of a tool for extracting and mapping locations from text documents, images, videos, online sources, and other sources. It requires specific details about the source, type of location extraction, mapping platform, and overall goals. The more information provided, the better the review can be tailored to the user's needs and experience. For example, a tool for extracting locations from text documents and mapping them on Google Maps would be highly recommended.
ReplyDeletetruck accident attorney near me
cuál es la ley de divorcio en nueva jerseyreferring to his parent’s house. Ideally, the location of the house could be extracted from a knowledge base. The extracted toponym “our house” should then be mapped to an absolute location name. This extracted piece of information can then provide us with the fact that people are evacuating from his parents’ area.
ReplyDeleteThis article provides a comprehensive overview of the challenges and methodologies involved in extracting and mapping location mentions from texts, focusing on social media data. The article outlines the process of location extraction and mapping, breaking it down into Toponym Extraction and Geoparsing sections. The inclusion of real-world examples, such as the Twitris campaign during the 2015 Chennai floods, enhances the practical relevance of the discussed methodologies. The article provides valuable insights into both supervised and gazetteer-based approaches for toponym extraction, highlighting their respective strengths and limitations. Technical details, such as the use of NLTK's cascaded chunk parser for syntactic parsing and fuzzy text matching for toponym extraction, are well-described but more clarity on implementation nuances could benefit readers less familiar with these tools. The discussion on ongoing research challenges, such as disambiguation during Geoparsing, adds depth to the article. The inclusion of figures, such as parse trees and mapped locations, enhances the visual appeal and understanding of the concepts discussed. The conclusion summarizes the key challenges and emphasizes the importance of addressing them for real-world applications, particularly in disaster relief scenarios. abogado de derecho de familia
ReplyDeletecontract disputesIt contains valuable, but implicit information for Disaster Response and Flood Modeling. Here the user provides the level of water during a storm surge. Knowledge-based inference supports the enrichment of this claim to determine that the water level is around 3 meters
ReplyDelete
ReplyDeleteTHIS BLOG dedicated to sharing insights, findings, and discussions on knowledge engineering and semantic technologies. It serves as a hub for researchers, academics, and professionals interested in exploring cutting-edge developments in these fields. Through articles, analysis, and commentary, the blog aims to foster collaboration and advance understanding in knowledge engineering and semantic technologies.
hearsay in court
dui lawyer fairfax va
tax and estate lawyer
henrico traffic lawyer
Speak with a family law attorney in Virginia to learn the requirements and particular procedure for appealing a protection order. Local legal aid programs might be able to help.
ReplyDeleteappealing a protective order in virginia
I appreciate you writing this write-up and also the rest of the website is really good. registros de divorcio nueva jersey
ReplyDeletevirginia dui attorneyThe approach is comprehensive, leveraging tools like Twitris and NLTK while integrating multiple data sources and knowledge bases for accurate location extraction. The text emphasizes the importance of text normalization to handle abbreviations, misspellings, and incomplete location references in social media content.
ReplyDeleteFinding references to locations inside textual data and connecting them to precise geographic coordinates on a map is the process of extracting and mapping location mentions from texts to the ground. Numerous applications, such as geographic information systems (GIS), natural language processing, and geographical analysis, depend on this activity. Text mining algorithms are usually used first to extract geographical mentions from unstructured textual data. To do this, named entity recognition (NER) algorithms may be used to locate and categorize locations such as cities, nations, or landmarks as well as entities inside the text. How to reduce a reckless driving ticket in Virginia
ReplyDeletedivorce lawyer arlington vaThis article uncovers some of the persisting challenges in the recovery of location information from content and context: Text normalization, ambiguous location information, Geoparsing, and the future steps of our research.
ReplyDeletedivorce lawyer arlingtonThis interdisciplinary research reduces manual labor and automates geospatial data extraction, offering practical benefits in fields like urban planning, disaster response, and social sciences. The research bridges the gap between unstructured textual information and structured geospatial data, offering significant implications for location-based decision-making and analysis
ReplyDeleteWhat is The Process of Divorce in New York , divorce begins by filing a summons and complaint, serving the spouse, negotiating terms, and finalizing with a court judgment, ensuring all legal requirements are met.
ReplyDeleteThis comment has been removed by the author.
ReplyDelete3rd dui in 10 years virginiaThe article outlines the process of location extraction and mapping, breaking it down into Toponym Extraction and Geoparsing sections. The inclusion of real-world examples, such as the Twitris campaign during the 2015 Chennai floods, enhances the practical relevance of the discussed methodologies.The Virginia DUI arrest records remain a matter of public record until a person takes action. They certainly will have the right, if they are acquitted, to file an expungement petition in the circuit court of that jurisdiction to have those arrest records expunged.
ReplyDeletePrincess Chelsea's cover of Whitetown is a delightful musical reimagining! Her unique style brings fresh life to the original, creating a captivating blend of nostalgia and innovation. The artistic interpretation showcases Chelsea's talent for reinventing classics while maintaining their essence. This cover is sure to enchant both longtime fans and new listeners alike. Protección Orden Nueva Jersey
ReplyDeletedivorce lawyer in hampton vaBy providing legal advice, representing clients in court, negotiating settlements, protecting their rights, managing emotions, and maintaining confidentiality, divorce lawyers from Vakilsearch can help clients achieve a successful outcome in their divorce case. Mapping events to locations in order to attach ground-based information to locations on the map will allow us to achieve the desired goal. In contrast to physical sensors, the resolution of social media data is a function of population rather than specialized infrastructure.
ReplyDeleteThe "Extracting and Mapping Location" tool is an exceptionally powerful and user-friendly solution for spatial data analysis and visualization. Its intuitive interface simplifies the process of extracting geographic data and converting it into detailed, accurate maps, making it accessible even for those with limited technical expertise. The tool's robust features, including customizable map layers, real-time data integration, and advanced analytical capabilities, enable users to gain valuable insights and make informed decisions based on location-based information
ReplyDeletecharlottesville spousal support lawyer
Charlottesville motorcycle accident lawyer
The technique of extracting and mapping location mentions from texts to the ground entails finding references to locations within textual data and linking them to accurate geographic coordinates on a map. This activity is essential for a variety of applications, including geographic information systems (GIS), natural language processing, and geographic analysis. protective order Virginia code
ReplyDeletevirginia dui recordsThe article outlines the process of location extraction and mapping, breaking it down into Toponym Extraction and Geoparsing sections. The inclusion of real-world examples, such as the Twitris campaign during the 2015 Chennai floods, enhances the practical relevance of the discussed methodologies.A Virginia DUI lawyer could help defendants to understand the potential effects of a DUI conviction on their driving privileges, what happens to their car after an arrest, and fight to protect those rights. They could also explain how driving is defined in these cases.
ReplyDelete"Great job on extracting and mapping locations! Your approach is efficient and insightful, making complex data much easier to visualize and understand. This work has a lot of potential applications and adds real value to any project. Looking forward to seeing more of your innovative solutions!" divorce new york no fault
ReplyDeleteThe text suggests a review or comment on "O-Cético: Ceticismo Localizado" based on themes of skepticism and localized skepticism. It emphasizes questioning assumptions and beliefs in specific contexts, encouraging critical thinking and understanding complex issues. manassas reckless driving lawyer Fighting for your rights, one case at a time. With a proven track record and unwavering dedication, I turn legal challenges into victories. Let's navigate the law together!
ReplyDeletehow to avoid paying alimony in marylandThe best way to avoid paying alimony in Maryland is to sign a prenuptial agreement. This is a document drafted by the couple before their marriage is made legal. This document includes the full disclosure of each individual's income and the assets each spouse will bring to the marriage.By thoroughly documenting your financial circumstances and showing that both parties will have a fair and sustainable post-divorce situation, you may be able to avoid alimony payments. It's crucial to work closely with a financial planner or attorney during this process to ensure all aspects are accurately represented
ReplyDeleteThe question is about extracting and mapping locations from a dataset or input, clarifying the specific types of locations and context to tailor the explanation or approach New York Uncontested Divorce Lawyer.
ReplyDeleteThe production is polished, with soulful melodies and poignant lyrics that resonate with anyone who has experienced love's highs and lows. Passmore's powerful and tender vocal delivery makes each line feel personal and relatable. The song's arrangement adds depth and highlights the transformative power of love. traffic lawyer fairfax va Your trusted advocate with a proven track record in navigating legal challenges. Committed to securing justice and delivering results for every client, every time.
ReplyDeleteVirginia Spousal Support Spousal support, also known as alimony or maintenance, is a payment made by one spouse to another after a divorce to help them maintain a reasonable standard of living. The purpose of spousal support is to help ensure that both spouses can meet their financial obligations after the divorce.Spousal support, whether ordered by the court or agreed to by the parties, can be paid in periodic (i.e., bi-weekly or monthly) payments for a set duration, such as four years; periodic payments for an unspecified duration; in the form of a lump sum award; or any combination of the above.The formula stated in § 16.1-278.17:1 is: (a) 30% of the gross income of the payor less 50% of the gross income of the payee in cases with no minor children and (b) 28% of the gross income of the payor less 58% of the gross income of the payee in cases where the parties have minor children in common.When the incomes qualify for spousal support, judges use specific formulas to calculate the exact amount of money that will be paid annually. Alimony is set at 30% percent of the higher-earning spouse's income minus half of the lower-earning spouse's income.
ReplyDeleteExtracting and Mapping Location Mentions From Texts to the Ground is a fascinating endeavor combining natural language processing (NLP) and geospatial technology. This process involves identifying location names or references in text, disambiguating them to ensure accuracy, and mapping them to specific geographic coordinates on a map. Key challenges include resolving ambiguities in place names and handling context-sensitive mentions like "the capital" or "near the river."
ReplyDeleteClass 1 Misdemeanor Virginia Reckless Driving
Virginia Reckless Driving
Isis Morales, popularly known as"Who Is Isis Morales, aka “New Trophy Wife" on social media platforms, has recently sparked a wave of online attention with her controversial allegations against her husband. The influencer, who has steadily gained a following for her content revolving around family life, relationships, and personal growth, has now become a trending topic for more dramatic reasons.
ReplyDeletevirginia cohabitation law A cohabitation agreement is often used when two parties are in a romantic relationship and living together, but do not have any intention in the foreseeable future of getting married. The reason it is used in Virginia is because Virginia does not recognize common law marriages.Since Virginia law fails to recognize cohabitation as either a marriage or civil partnership, a cohabitation agreement can provide unmarried couples with a layer of protection they would not otherwise be entitled to.Cohabitation is an arrangement where people who are not married, usually couples, live together. They are often involved in a romantic or sexually intimate relationship on a long-term or permanent basis.A proof of cohabitation is any document that proves that the primary place of residence is the same for all of the individuals included in your claim. This can be bills, bank or credit card statements, identification documents, rental agreements, or other official documents including the name and home address.Affidavit of Cohabitation: The couple must prepare and sign a joint affidavit affirming that they have been living together for at least five years and that there are no legal impediments to their marriage. This affidavit must be notarized.The cohabitation agreement should clearly set out the following: that the agreement does not constitute a marriage; aspects regarding any joint property owned by the couple, such as a house. If they are buying or renting a house together, it is best to register or lease the house in both names
ReplyDeleteprenuptial agreement virginia "Premarital agreement" means an agreement between prospective spouses made in contemplation of marriage and to be effective upon marriage. A prenuptial agreement, also known as a premarital agreement, is a legal contract that couples in Virginia can enter into to address financial and property matters before getting married. A premarital agreement is a legal, written agreement signed by prospective spouses. Premarital agreements are also known as prenuptial agreements or prenups. Virginia premarital agreements are commonly used to address marital issues and protect one's property or financial obligations
ReplyDeleteYour information you’ve provided are much appreciated. Need a trusted family lawyers in virginia? Let our skilled team offer compassionate and effective representation for your family law needs.
ReplyDeleteThe legal ramifications of ending a marriage, including property distribution, child custody agreements, and other associated issues, are handled by divorce attorneys. They advocate your interests in court or try to negotiate fair settlements between spouses. Having a knowledgeable attorney at your side is crucial, especially considering the emotional and legal difficulties that come with divorce. An experienced divorce attorney can offer professional legal assistance and direction if you're dealing with a code of virginia emergency protective order . Get in touch with us now to find out more.
ReplyDeleteGreat insights! Programming assignments can be tricky, especially when tackling challenging concepts and tight deadlines. A reliable Programming Assignment Helper can provide valuable support, helping students understand coding problems and deliver high-quality solutions. It's a fantastic option for anyone looking to excel in their programming tasks.
ReplyDeleteVA code solicitation of a minor
ReplyDeleteA "premarital agreement" is a contract between potential spouses that is made with marriage in mind and takes effect upon marriage. In Virginia, a prenuptial agreement, sometimes referred to as a premarital agreement, is a formal contract that couples can sign to handle money and property issues before to marriage. A prenuptial agreement is a formal written contract that potential spouses sign. Prenuptial agreements, or prenups, are another name for premarital agreements. Premarital agreements in Virginia are frequently utilized to resolve marital problems and safeguard one's assets or debts.
This article uncovers some of the persisting challenges in the recovery of location information from content and context: Text normalization, ambiguous location information, Geoparsing, and the future steps of our research.
ReplyDeleteIf you need any legal help, kindly visit our page. No matter what, our team lawyers will perform wonderfully. We provide best legal services in VA, Maryland and NJ as much as you would expected. Our team lawyers can understand the charges against you and explore the options for the charges.
assault and battery first offense
Divorce can be one of the most challenging experiences in a person's life, and having the right lawyer by your side can make a significant difference. Falls Church, VA, is home to many legal professionals who specialize in family law, including divorce. divorce lawyer falls church va
ReplyDeleteGeographic references in written content must be found and then linked to actual locations in order to extract and map location mentions from texts to the ground. what is sexual contact This method is frequently applied in disciplines like data science, digital humanities, and geography where comprehending spatial allusions in books, news stories, and social media can yield insightful information.
ReplyDeleteGoing through a divorce can be a challenging and emotional process. Having the right legal support can significantly affect how smoothly and fairly your case proceeds. If you seek a divorce lawyer in Prince William County, VA, this guide outlines key considerations to help you find the right legal advocate for your situation. prince william county family lawyer
ReplyDeleteIn Virginia, provision, or spousal help, is monetary help one life partner might be expected to pay the other after separate. The court thinks about elements like the length of the marriage, the monetary and non-monetary commitments of every companion, and the beneficiary life partner's necessities and capacity to help themselves. Support can be granted on an impermanent or long-lasting premise, contingent upon the conditions. The sum and term are resolved in light of decency and the particular realities of the case. virginia alimony
ReplyDeleteA unique project that combines geospatial technology and natural language processing (NLP) is Extracting and Mapping Location Mentions From Texts to the Ground. In order to assure accuracy, geographical names or references in text must be identified, disambiguated, and mapped to precise geographic coordinates on a map. Human trafficking lawyer, Resolving location name ambiguities and managing context-sensitive references like "the capital" or "near the river" are major obstacles.
ReplyDeleteIn New York, you must serve your spouse, provide proof of service, and file the required divorce documents with the Supreme Court in order to receive a divorce decree. Your divorce will be finalized when a judge issues the Judgment of Divorce following a court review.
ReplyDeleteHow to Obtain Divorce Decree in New York
"Extracting and Mapping Locations is a powerful technique used in data analysis, geospatial mapping, and location-based services. By extracting specific location data from various sources (such as GPS, addresses, or geographic datasets) and mapping it visually, businesses and researchers can gain valuable insights into patterns, trends, and spatial relationships. This method is especially useful for urban planning, marketing strategies, delivery optimization, and more. Whether you're working with real-time data or historical records, mapping locations can enhance decision-making and strategic planning."
ReplyDeletevirginia personal injury statute of limitations
When it comes to extracting and mapping location mentions from texts to the ground, it's essential to consider the context and relevance of the information shared. In a blog comment, readers may include various location references that can add depth to the conversation. By utilizing tools like natural language processing and geotagging, bloggers can extract these mentions and visualize them on a map for better understanding and engagement. This not only enhances the reader's experience but also provides valuable insights into the geographic distribution of opinions and experiences shared in the comments section. Overall, incorporating location mapping in blog comments can enrich the content and foster a more interactive and informative platform for both creators and readers alike.
ReplyDeletedui lawyer fairfax va
When it comes to extracting and mapping location mentions from texts to the ground, it's essential to consider the context and relevance of the information shared. In a blog comment, readers may include various location references that can add depth to the conversation. By utilizing tools like natural language processing and geotagging, bloggers can extract these mentions and visualize them on a map for better understanding and engagement. This not only enhances the reader's experience but also provides valuable insights into the geographic distribution of opinions and experiences shared in the comments section. Overall, incorporating location mapping in blog comments can enrich the content and foster a more interactive and informative platform for both creators and readers alike.
ReplyDeletereckless driving lawyer lexington va
The blog post titled "Extracting and Mapping Locations from Wikipedia" discusses a method for identifying and visualizing location data within Wikipedia articles. By leveraging natural language processing techniques, the approach extracts geographic information, enabling the creation of detailed maps that represent the spatial distribution of various topics covered in Wikipedia. Middlesex County Reckless Driving Lawyer can lead to severe penalties, including hefty fines, license suspension, and even incarceration. The Law Offices of SRIS, P.C. offers experienced legal representation to protect your rights and strive for a favorable outcome.
ReplyDeleteUsers can see geographic trends, patterns, or linkages within the text by projecting these coordinates onto a visual platform, which provides a clear spatial depiction of the locations discussed. This method is especially useful in domains where knowing the geographic context of data is essential, such as social media analytics, news monitoring, and geospatial analysis.
ReplyDeletevirginia sex crimes laws
If you're a student looking for reliable academic support, I highly recommend New Assignment Help Australia. I had a fantastic experience with their writing team when I needed assistance with my psychology essay. Their Assignment Help service was a game-changer for me, as their experts provided a detailed and well-structured paper that improved my understanding of the subject. The service was quick, professional, and affordable, making it a great option for students. I will definitely be using their assistance again for my upcoming assignments.
ReplyDeleteExtracting and mapping location mentions from texts to the ground helps create accurate geospatial data. This process enhances location-based services, improves navigation, and allows for better analysis of trends, making it valuable for industries like tourism, logistics, and urban planning.carroll condado dui va
ReplyDeleteA neutral mediator assists couples in resolving matters such as alimony, property distribution, and custody outside of court in New York through divorce mediation. It's a less confrontational, more affordable option that gives couples more control over the result.
ReplyDeletenew york state divorce mediation
Your writing always brings clarity to complex topics. This was another excellent post!
ReplyDeleteDrug Manufacturing Lawyer
By projecting these coordinates onto a visual platform, which offers a clear spatial representation of the areas described, users can see geographic trends, patterns, or linkages within the text. online solicitation of a minor virginia, This approach is particularly helpful in fields like social media analytics, news monitoring, and geospatial analysis where understanding the geographic context of data is crucial.
ReplyDeleteStreamline your business journey with GST Registration and Partnership Firm Registration. Get your Barcode Registration done, or opt for Udyam Registration to grow your business effortlessly
ReplyDeleteGreat post! Your explanation of economic theories was clear and very engaging.It’s always helpful to see real-world applications tied into the concepts.For students needing extra guidance, Economics assignment help can be a valuable resource.We offer expert-written solutions to support learning and boost grades.Looking forward to more insightful content from you.
ReplyDeleteThis work supports a wide range of applications, including disaster response, historical research, and urban planning, allowing users to visualize how and where events unfold in the physical world.
ReplyDeleteindecent exposure laws
family lawyer virginia who cares: dealing with divorce, child custody, support, separation, etc. We’ll help you understand rights, options, guide paperwork, court stuff. Fighting for fairness, keeping your children’s well-being first. Don’t navigate it alone, get someone you can trust.
ReplyDeleteIt discusses techniques for parsing location names from articles, social media, or historical documents, and how those names are matched to actual places using mapping tools and databases. The process helps visualize patterns, track events, and enrich data-driven storytelling.
ReplyDeletenewport news virginia laws
Sermon Blog is an online platform sharing religious teachings and spiritual reflections. It features sermons, devotionals, and interpretations of scripture. The blog aims to inspire faith, moral growth, and community connection. It serves pastors, believers, and readers seeking daily spiritual guidance.
ReplyDeleteonline vinyasa yoga classes in Bali
yoga classes for beginners in seminyak
This comment has been removed by the author.
ReplyDeleteExtracting and Mapping Location Mentions From Texts To The Ground offers an insightful exploration of how unstructured textual data can be transformed into meaningful geographic intelligence. The content effectively highlights the challenges and innovations involved in identifying place names, resolving ambiguities, and accurately linking them to real-world locations. By bridging natural language processing with geospatial analysis, it demonstrates strong potential for applications in research, media monitoring, and data-driven decision-making.
ReplyDeletevolvo specialist
Extracting and Mapping Location Mentions From Texts To The Ground is a highly insightful and methodical piece that explores the intersection of natural language processing and geospatial analysis. The work effectively demonstrates how textual data can be transformed into actionable geographic information, highlighting both the technical challenges and practical applications of location extraction and mapping
ReplyDeleteArc fault Breakers buyers in Alabama
Blog knoesis is the official blog of the Kno.e.sis Center, a research institute focused on data science and AI. It shares insights on knowledge graphs, machine learning, and semantic technologies. The blog features research updates, publications, and project highlights. It is written by researchers, faculty, and industry collaborators. Blog knoesis helps bridge academic research with real-world applications.
ReplyDeleteWorkers Compensation for Staffing Agencies Phoenix, Arizona
Workers Comp for Staffing Agencies Little Rock, Arkansas
“Extracting and Mapping Location Mentions From Texts to the Ground” is a compelling and technically insightful piece that explores how geographic information can be identified within unstructured text and accurately linked to real-world locations. The review highlights the article’s clear explanation of techniques such as named entity recognition, geocoding, and disambiguation, which are essential for turning textual place references into mappable data.
ReplyDeleteArc fault Breakers buyers in Phoenix
Thanks for sharing this valuable content. Your input helps uncover hidden insights and enhances the process of implicit information extraction. By providing such details, you contribute to deeper understanding, knowledge discovery, and improved decision-making
ReplyDeleteImport Export Agent
Great article! I really enjoyed reading this post. The content is informative, well-organized, and easy to understand. It's clear that a lot of time and effort went into creating such valuable information. I appreciate the practical approach and the engaging writing style, which kept me interested from beginning to end. Thank you for sharing your knowledge and insights with your readers. FreeCodesLab
ReplyDeleteArticles like this are always helpful and worth reading. I'm looking forward to exploring more content on your blog. Keep up the excellent work, and I wish you continued success with your future publications and updates.