
The meaning of a social media post can be a function of location. For example, the meaning of "The Main Street bridge is closed" is ambiguous without establishing exactly which bridge is in question (The one in Danville, VA or in Columbus, OH). At the same time, location information metadata is sparse, forcing analysis of social media content and context to disambiguate alternative mappings. This article uncovers some of the persisting challenges in the recovery of location information from content and context: Text normalization, ambiguous location information, Geoparsing, and the future steps of our research.
Consider the Tweet in Figure 1. It contains valuable, but implicit information for Disaster Response and Flood Modeling. Here the user provides the level of water during a storm surge. Knowledge-based inference supports the enrichment of this claim to determine that the water level is around 3 meters (to the height of a first floor)1. If we knew the location of Ganapathi colony, this quantitative data can inform a storm surge model to predict the direction of the surge and the danger it might pose.
Consider the Tweet in Figure 1. It contains valuable, but implicit information for Disaster Response and Flood Modeling. Here the user provides the level of water during a storm surge. Knowledge-based inference supports the enrichment of this claim to determine that the water level is around 3 meters (to the height of a first floor)1. If we knew the location of Ganapathi colony, this quantitative data can inform a storm surge model to predict the direction of the surge and the danger it might pose.
#ChennaiRainsHelp water hitting first floor. need to evacuate Ganapathi colony. @ChennaiRains @ndtv pic.twitter.com/rNvx4i4JVH— Balaji (@blaji) December 2, 2015
Fig. 1: An example tweet from Twitris campaign of Chennai Flood 2015.
At Kno.e.sis center, one of the goals of our NSF-funded project (Social and Physical Sensing Enabled Decision Support) is to make information available in social media accessible to first-responders to prioritize relief efforts. Mapping events to locations in order to attach ground-based information to locations on the map will allow us to achieve the desired goal. In contrast to physical sensors, the resolution of social media data is a function of population rather than specialized infrastructure. In the case of lack of sensor/IoT coverage or malfunctioning of sensors, citizen sensing can provide information about ground status to compensate for missing data.
Using Twitris, Kno.e.sis’ robust semantic social web platform that has been used in a number of real-world scenarios, we collect real-time, event-centric twitter data to understand social perceptions. During the 2015 Chennai floods, we created a Twitris campaign that collected around 508K relevant tweets. Determining location is an important part of making these tweets informative. Location extraction and mapping is performed in two steps: Toponym extraction and Geoparsing.
Toponym Extraction
Toponym extraction is the process of extracting names of places from texts such as street names, points of interest (POI), cities, countries, and so on. There are two traditional ways to extract toponyms from texts: a supervised approach and an gazetteer-matching approach.
Supervised approaches. In the supervised approach, we train the model using manually annotated data of location mentions [1], Supervised approaches tend to suffer from the underestimation of missing data. They require sufficient amount of annotated data from the same data source (e.g., microblog text), to enable location detections from similar data sources. However, the gazetteer approach discussed next has its own difficulties and issues that must be solved to extract locations from texts efficiently.

Fig. 2: Syntactic Parse tree built using NLTK's cascaded chunk parser.
Gazetteers approaches. In the gazetteer approach, we extract location mentions on the fly without using any training dataset. Gazetteer approaches often use syntactic parse trees (for noun phrase extraction), direction and distance markers, gazetteers, dictionaries and many other knowledge bases in order to extract locations from texts [2-4]. Figure 2 shows part of the parse tree built using NLTK of the tweet text in Figure 3. Parsing the tweet text allows us to find noun phrases using the NLTK’s cascaded chunk parser. The parser matches a set of predefined rules to text. For example, the rule ( VP: {<VB.*><NP|PP|CLAUSE>+$} ) allows us to detect and extract the noun phrase (NP) “SRM university” which follows the preposition (PP) “Near”.
Please evacuate us from area Near SRM university, kattankulathur. No food.. No current.. Nothing is here . #ChennaiRains #ChennaiRainsHelp— Rohit kumar singh (@imRohit09) December 1, 2015
Fig. 3: Tweet mentioning the toponyms “SRM university” and “kattankulathur”.
Similarly, direction and distance markers allow us to retrieve toponyms the markers are pointing at. For example, in Figure 4. The direction marker “south of” points at the toponym “101 Fwy” which is then added to our list of potential geo-parsable toponym names.
THIS JUST IN: Power out in #StudioCity after reports of loud explosion in area south of 101 Fwy between Woodman Ave and Coldwater Canyon.— ABC7 Eyewitness News (@ABC7) April 7, 2016
Fig. 4: Tweet mentioning a toponym (“101 Fwy”) pointed at by a direction marker
Two challenges arise in Toponym extraction: Text normalization and ambiguous location information.
Text normalization. Text normalization involves subtasks such as abbreviations and acronyms expansion and misspelling corrections. Figure 5 shows an example of a tweet with such difficulties. The author of the tweet used “Rd” as an abbreviation of “road”. Moreover, the text “Kilpauk Garden” is incomplete relative to the Gazetteer name “Kilpauk, Aspiran Garden Colony”2.
2 ppl need to be evacuated frm #21, New Avadi Rd, Kilpauk Garden (Nr. Zam Zam Bakery) Contact 9841546767 #ChennaiRainsHelp #chennairains— Raj!n! Followers™ (@RajiniFollowers) December 1, 2015
Fig. 5: An example tweet with abbreviations (Rd) and incomplete information (Kilpauk Garden).
Locations can also be embedded in hashtags or usernames. For example, both @yankeestadium and #YankeeStadium refer to the location name “Yankee Stadium”. Therefore, such location mentions can also be extracted using a word segmentation (tokenization) method. The method uses a classifier on unigram and bigram language models of word frequencies to find word boundaries.
Locations can also be embedded in hashtags or usernames. For example, both @yankeestadium and #YankeeStadium refer to the location name “Yankee Stadium”. Therefore, such location mentions can also be extracted using a word segmentation (tokenization) method. The method uses a classifier on unigram and bigram language models of word frequencies to find word boundaries.
Ambiguous Location Information. Location information is not always explicit. The relative directionality and distance content noted above hints at this problem. Consider the following tweet (Figure 6) as a more challenging example:
Our house in Chennai fully flooded. Everyone evacuated safely. My brother trying to get there from Mumbai...— Karun Chandhok (@karunchandhok) December 2, 2015
Fig. 6: A tweet showing an ambiguous mention of a location.
In this example, a renowned author (Indian racing driver Karun Chandhok) is referring to his parent’s house. Ideally, the location of the house could be extracted from a knowledge base. The extracted toponym “our house” should then be mapped to an absolute location name. This extracted piece of information can then provide us with the fact that people are evacuating from his parents’ area. For another example of using a knowledge base (or location database) to identify a building name (Nariman House) is shown in Figure 2 of this article on Citizen Sensing.
Geoparsing
Geoparsing contrasts with geocoding, and both follow toponym extraction. Geocoding works with unambiguous location references such as postal addresses to specify a location on Earth using coordinates (latitude and longitude). Geoparsing is similar to Geocoding but differs in that it works with ambiguous location references in unstructured texts (such as tweets).
Geoparsing can be performed through a gazetteer matching process that allows us to retrieve all the metadata of the matched location. OpenStreetMap, for example, provides information such as the bounding box, the latitude and longitude, the full address, the class of the location name (Map Features), and the full display name of the matched toponym. The information extracted after a successful gazetteer matching pinpoints the toponym on the map and attaches to it the extracted metadata. The following map (Figure 7) shows the mapped toponym from the tweet in Figure 5.
Geoparsing can be performed through a gazetteer matching process that allows us to retrieve all the metadata of the matched location. OpenStreetMap, for example, provides information such as the bounding box, the latitude and longitude, the full address, the class of the location name (Map Features), and the full display name of the matched toponym. The information extracted after a successful gazetteer matching pinpoints the toponym on the map and attaches to it the extracted metadata. The following map (Figure 7) shows the mapped toponym from the tweet in Figure 5.
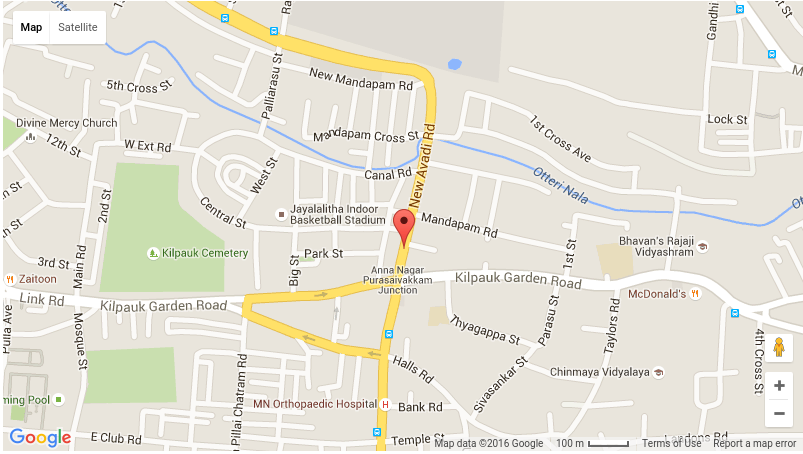
Fig. 7: Pinpointing the full location name of the extracted toponym from the tweet in Figure 5: “No. 17/7, New Avadi Road, Kilpauk, Aspiran Garden Colony, Kilpauk, Chennai, Tamil Nadu 600010, India”
A typical gazetteer matching task requires complex text normalization and missing data restoration. To overcome some of the difficulties posed by Twitter data we typically use fuzzy text matching during toponym extraction, in addition to the previously discussed text normalization process. As for the incompleteness of gazetteers, a combination of one or more additional knowledge bases can be used. An example of such dictionaries is a list of points of interest3 that can be retrieved from an external data source.
Other things our research is addressing is the problem of disambiguation during Geoparsing. If a toponym name has many records in the gazetteer, the method should reasonably disambiguate which location the tweet was referring to. This problem includes the Whole-Part Relationship (i.e., which section of the road and which campus of a university). Using the provided context from text as shown in Figure 4, where the toponym “101 Fwy” is supposed to be “between Woodman Ave and Coldwater Canyon”, can tremendously help in solving such problems. Our research is currently investigating such problems and possible solutions.
Conclusions
Toponym extraction and Geoparsing require more than text normalization and the retrieval of unambiguous location names from the text. The disaster relief scenario aids in the identification of several important, and the research challenges yet to be solved well, such as ambiguous location information and more advanced Geoparsing disambiguations. The Kno.e.sis center's mission “Computing for Human Experience”, drives the recognition of these challenges while providing ground impact beyond lab implementations.
1 The issue of reliability and trustworthiness of the extracted information are relevant to our project but are not discussed here.
2 The correct location found using Google Maps goo.gl/AN9Gxr
3 Area specific points of interest (for example, in Chennai) are typically businesses, hospitals, shopping malls, etc.
References:
[1] Lingad, John, Sarvnaz Karimi, and Jie Yin. "Location extraction from disaster-related microblogs." In Proceedings of the 22nd international conference on World Wide Web companion, pp. 1017-1020. International World Wide Web Conferences Steering Committee, 2013.
[2] Gelernter, Judith, and Shilpa Balaji. "An algorithm for local geoparsing of microtext." GeoInformatica 17, no. 4 (2013): 635-667.
[2] Gelernter, Judith, and Shilpa Balaji. "An algorithm for local geoparsing of microtext." GeoInformatica 17, no. 4 (2013): 635-667.
[3] Shervin Malmasi, Mark Dras. “Location Mention Detection in Tweets and Microblogs”. Computational Linguistics. Volume 593 of the series Communications in Computer and Information Science pp 123-134. Springer February 2016.
[4] Middleton, Stuart E., Lee Middleton, and Stefano Modafferi. "Real-time crisis mapping of natural disasters using social media." Intelligent Systems, IEEE 29, no. 2 (2014): 9-17.
Parent Project
- 7:38:00 PM
- 79 Comments

